Octave Convolution:是否名副其实?「八度卷积」
论文名称:Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
作者:Yunpeng Chen, Haoqi Fan , Bing Xu , Zhicheng Yan, Yannis Kalantidis, Marcus Rohrbach, Shuicheng Yan , Jiashi Feng Facebook AI, National University of Singapore, Yitu Technology
摘要和介绍
-
自然图像中,信息主要以不同的频率传递,高频通常使用细节编码,低频通常使用全局结构编码,而卷积的特征输出也可看做是不同频率信息的混合。

-
因此提出了 OctConv,将特征图输出分为高频和低频,分别对这两个部分进行处理,在降低计算量的同时保持参数与普通卷积相同,通过设计高低频之间的信息交换方式,提高了一定的性能。其中,低频被储存在低分辨率张量(大小为原图的四分之一)中,以减少空间冗余,同时能够扩大感受野(相较于原图大小);
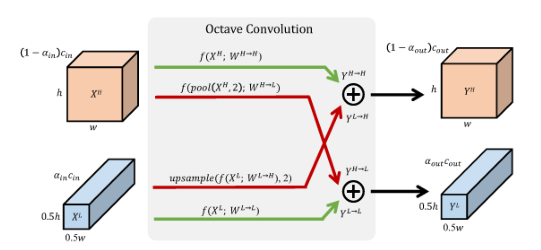
基本结构和实现细节
超参数:
和 分别表示输入图片与输出图片中低频部分所占通道的比例
在第一层 OctConv 中,需要将 设置为 0, 设置为
在最后一层 OctConv 中,需要将 设置为 , 设置为 0
在中间层的 OctConv 中,
高低频之间的信息交换
高频到低频:将高频特征下采样两倍,卷积得到 ,与低频特征图相加
低频到高频:将低频特征上采样两倍,卷积得到 ,与高频特征图相加
参数分配
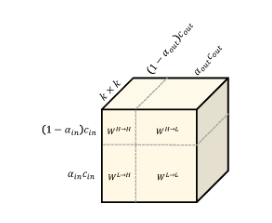
上图表示了 OctConv 的参数分配
参数量为
参数量为
参数量为
参数量为
其总和即为 ,与普通卷积相同。
其他
Octave Convolution 对分组卷积,深度可分卷积等同样适用。
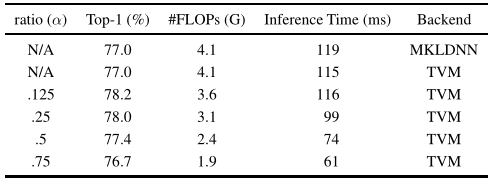
可以看到随着 的增加,低频信息占比不断增加,由于低频信息的分辨率低,于是计算量不断减小,但是 �过大会导致精度的下降。
代码
实际上就是用四个卷积来实现一个卷积,简单的代码大概如下
class Frist_octaveconv(nn.Module):
def __init__(self, in_ch=3, out_ch=3, ker_size=3, alpha=0.5, padding=0, stride=1, group=1, bias=True):
super(Frist_octaveconv, self).__init__()
self.l_out = int(alpha * out_ch) #低频率输入通道数
self.h_out = out_ch - self.l_out #高频率输入通道数
self.downsample2x = nn.AvgPool2d(
kernel_size=2, stride=2, ceil_mode=True) #两倍下采样
self.hh = nn.Conv2d(in_ch, self.h_out, ker_size,
stride, padding, bias=bias) #高分辨率到高分辨率
self.hl = nn.Conv2d(in_ch, self.l_out, ker_size,
stride, padding, bias=bias) #高分辨率到低分辨率
def forward(self, x):
yh = self.hh(x)
yl = self.hl(self.downsample2x(x))
return (yh, yl)
class Last_octaveconv(nn.Module):
def __init__(self, in_ch=3, out_ch=3, ker_size=3, stride=1, alpha_in=0.25, padding=0, group=1, bias=True):
super(Last_octaveconv, self).__init__()
self.alpha = alpha_in
self.l_in = int(self.alpha * in_ch)
self.h_in = in_ch - self.l_in
self.hh = nn.Conv2d(self.h_in, out_ch, ker_size,
stride, padding, bias=bias)
self.lh = nn.Conv2d(self.l_in, out_ch, ker_size,
stride, padding, bias=bias)
def forward(self, x):
xh, xl = x
yh = self.hh(xh)
t = self.lh(xl)
yl = F.interpolate(t, size=yh.shape[2:], mode='nearest')
return yh + yl
class Octave_conv(nn.Module):
def __init__(self, in_ch=3, out_ch=3, ker_size=3, padding=0, alpha_in=0.25, alpha_out=0.25, stride=1, group=1, bias=True):
super(Octave_conv, self).__init__()
self.downsample2x = nn.AvgPool2d(
kernel_size=2, stride=2, ceil_mode=True)
self.l_in = int(alpha_in * in_ch)
self.h_in = in_ch - self.l_in
self.l_out = int(alpha_out * out_ch)
self.h_out = out_ch - self.l_out
self.hh = nn.Conv2d(self.h_in, self.h_out, ker_size,
stride, padding, 1, group, bias)
self.hl = nn.Conv2d(self.h_in, self.l_out, ker_size,
stride, padding, 1, group, bias)
self.ll = nn.Conv2d(self.l_in, self.l_out, ker_size,
stride, padding, 1, group, bias)
self.lh = nn.Conv2d(self.l_in, self.h_out, ker_size,
stride, padding, 1, group, bias)
def forward(self, x):
xh, xl = x
xhh = self.hh(xh)
t = self.downsample2x(xh)
xhl = self.hl(t)
xll = self.ll(xl)
xlh = self.lh(xl)
xlh = F.interpolate(xlh, size=xhh.shape[2:], mode='nearest')
yh = xhh + xlh
yl = xll + xhl
return (yh, yl)
问题
实际上论文中并没有涉及更多的高低频信息,仅仅在开篇引入,没有任何后续证明(或许是通过学习来提取相应的高低频信息),个人感觉仅仅是一种巧妙的分组思想。
也并非所说的即插即用,除了卷积层需要进行改动之外,各种池化和上采样等都需要进行改动,以适应分组的特征图。